I have been noticing that there is a lot of misunderstanding around LLMs and their inference infrastructure. Even seasoned AI application engineers tend to underestimate the fundamental lack of knowledge on how LLM inferencing works and how most of the known inference engines work and differ. I wanted to give my 2 cents on why the choice of inference engines is not as easy as
Just use Ollama bro LOL
especially if the goal is to self-host one of the open weight models and create production-ready infrastructure.
And to start off this post with a hot take: I think if you were to swap more preferred models like Claude Opus 4.6 by Anthropic with one of the open source models like Qwen 3.6 27B, even without bringing out the big guns like MiniMax 2.7, GLM 5.1, or DeepSeek V4 Pro, most people would not even notice the difference for daily tasks.
While the comparison is complex and again not easy, as the efficiency and usability of these models differ heavily on post-training for specific tasks, open source models have been packing a punch and are not toys anymore. People have found serious use cases, and it is quite freeing not to have to worry about rate limits and quotas. So what does this rambling have to do with the choice of a proper inferencing framework? Well, everything. Inference platform is the start of choosing a local inference strategy. Unfortunately, if you want top-of-the-line performance without sacrificing quality of outputs, you need to dig deep into the nuances of these frameworks, and there are quite a lot of pitfalls you have to navigate through.
Before you choose
Two of the main components of local inferencing are: GPU/APU/XPU/TPU and the corresponding stack. If you have Apple Silicon (APU, or MLX or Soc APU), there are specialized frameworks like mlx, which has extensive community engagement regarding specialized variants of quantized models. Same goes for Intel and XPU (shoutout to their AutoRound team with int4). While Google and their TPU architecture have been sort of secret, and elite magicians with their JAX optimizations do not interact with normal humans like us, I, as a consumer, hope there is more competition in the domain. Obviously, the safest pick right now is NVIDIA and its Blackwell architecture. With native hardware support for NVFP4, quantization is not just software magic. Nothing has shaken me more than the performance out of NVFP4-optimized Qwen 3.6 on GB10 (DGX Spark). Within weeks, Red Hat and NVIDIA cooked so well, Qwen 3.6 27B went from 9 tok/s (unusable) to 20 tok/s. And with MTP enabled and an optimized MTP drafting model, I see spikes in certain tasks of around 35 tok/s. Substantial gain.
So good for you, how do I make good choices?
If you are looking into getting your own GPU stack for the age of agentic workflows, consider the following points.
GPU Budget
There is a lot of investment in R&D regarding the right optimizations for GPU hardware right now, therefore the recommendation about the best GPU for your use case might be superseded quite fast. Architectures like MoE or dense models require their own set of GPU scheduling optimizations, which is why every GPU will perform differently. An RTX 5090 by NVIDIA will absolutely crush Intels Arc B70 Pros even though both GPUs have 32GB of VRAM. There are lots of parameters you need to look into before you decide to buy.
- VRAM: The most important part about making prod-grade inference infra is being able to fit all model layers in the GPU. This will significantly boost TTFT and token throughput. More is better, but also more expensive.
- Memory Bandwidth: Just having more memory will not help much if the bandwidth is not adequate. The same model on GDDR7 performs significantly faster than on GDDR6.
- Processing Units: Different vendors use different terms like tensor cores(NVIDIA), matrix units (Intel), matrix cores (AMD), etc. All of these are units that actually process vectors.
Because of the way LLM inferencing works, each of these factors affects different phases of output generation. Prefill is typically more compute-bound, while decode is often more memory-bandwidth- and KV-cache-bound. Capacity matters because the model and cache must fit, but bandwidth and cache efficiency heavily shape decode throughput.
To decide what platform you want to invest in, use the following chart:
| Budget | Platform | Vendor | Comment |
|---|---|---|---|
| Very tight (less than 1.5k €/month) | Rent a Cloud GPU | NVIDIA | CUDA |
| Tight (up to 1,500€) | XPU | Intel, AMD | Maturing software stack, not quite there yet |
| Moderate (up to 3,000€) | GPU | NVIDIA | RTX 40 generation cards |
| Average (up to 10,000€) | GPU | NVIDIA | RTX Pro Blackwell |
| High (> 10,000 €) | GPU | NVIDIA | Grace Blackwell or Hopper |
This chart is obviously very much dependent upon the ongoing DRAM shortage and pricing dynamics related to that. Also please don't beat me up because of OPEX vs CAPEX. I am not a guy in finance.
Power Consumption of Local Infrastructure
Before you decide on a GPU platform, you might want to look into your GPU's power draw. The power efficiency of different GPU platforms poses a massive difference in the monthly electricity bill. Newer cards are more efficient at the same TOPS and are worth more in the long run. If you have been observing GPU prices in the market, you might have noticed the influx of H100/H200s in marketplaces after the B200 was announced, even being significantly more expensive. So a cheaper older graphics card might be less worth it than newer, more efficient cards in the long run.
Infrastructure Maintenance
A GPU by itself will not work. You need CPU, RAM, disks, networking, etc. to make it all work. Making good choices with these parts is very crucial for an efficient system. And plan ahead for eventual failures/re-investments.
Engineers/Staff
This should be clear by itself. The infra will not manage/monitor itself.
Inference Frameworks
There are many serious inference frameworks to choose from (and ollama is not one of them, it is just a nice packaging of llama.cpp). Main differences lie mostly between optimized model format, support for quantizations, concurrency, decoding strategy, etc.
LLM Output Generation Flow
flowchart LR
A[Request] --> B[Tokenizer]
B --> C[Prefill]
C --> D[KV Cache]
D --> E[Scheduler / Batching]
E --> F[Decode Loop]
F --> D
F --> G[Output]
Frameworks in Close-up
| Framework | USP | When to choose |
|---|---|---|
| vLLM | High throughput serving | General purpose multi-user multi-tenant inference |
| llama.cpp | Portable GGUF-based quantization-first ecosystem | Consumer-grade GPUs, lower concurrency requirements |
| TensorRT-LLM | Best NVIDIA performance | You have NVIDIA GPU |
| SGLang | Structured, programmed inference for complex workflows | Agentic pipelines, etc. |
I have not included many of the other runtime-optimized inference frameworks as they are too niche.
Because of the complexity of setting things up, practically you have two options: If you have less complex workflows and just want to have 2-3 RAG chatbot users, llama.cpp would be an easy choice. If you want a bigger ecosystem with more concurrency, choose vLLM.
Why I prefer vLLM
TensorRT comes with free deep hardware tuning pain. Also I do not need to squeeze every matmul cycle out of every GPU in the datacenter. I do not like pain. I also prefer Anthropic-style /v1/messages and OpenAI-compatible responses and completions endpoints.
Because of the complexity of setting things up, vLLM is the practical choice when you want a real multi-user agent/ RAG-chatbot server without turning infra into a hobby project. The main reason people pick it is PagedAttention, which makes KV-cache memory management much more efficient, so you can serve more requests on the same GPU without wasting memory. The second big thing is continuous batching: instead of waiting for fixed batches, vLLM keeps filling the GPU while requests are coming in, which is why concurrency and throughput are so much better than naive serving. It also has a good serving ecosystem around it, including OpenAI-compatible APIs, so plugging it into existing apps is usually straightforward. In short, if you want more than a couple of users, decent scale, and as little pain as possible, vLLM is usually the default sane choice.
In this blog, Red Hat explains the exact technical differences between llama.cpp and vLLM.
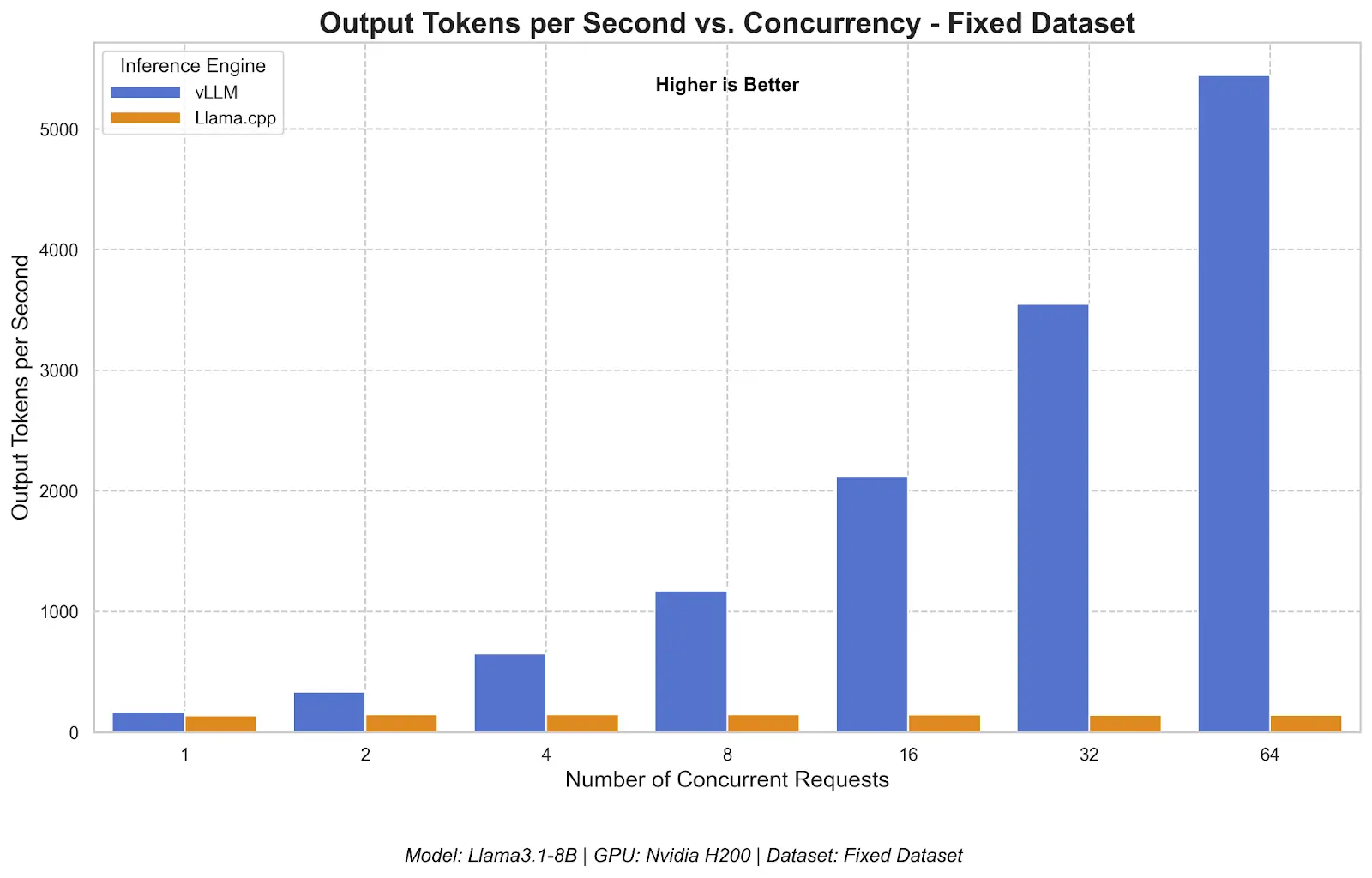
As we can see in the graph, for llama3.1-8B on NVIDIA H200 at 64 concurrent requests, vLLM serves at over 5500 tok/s, while llama.cpp is at around 50 tok/s. At 1 concurrency, the difference is marginal. This underlines our statement from before.
Conclusion
In the end, there is no universal “best” inference engine, only the one that best matches your hardware, workload, concurrency needs, and tolerance for operational pain. The model is only one part of the equation; the runtime, quantization strategy, memory management, batching behavior, and hardware stack all directly shape the actual user experience.
That is why “just use Ollama” is fine advice for quick experiments, but not for serious self-hosted production systems. Once you care about throughput, TTFT, multi-user concurrency, cost efficiency, and maintainability, inference stops being a toy problem and becomes an infrastructure problem. And infrastructure problems rarely have meme-level answers.
So if you are building something real, take the inference layer seriously. Understand your hardware, understand your model format, understand your workload, and pick the framework that optimizes for your constraints instead of someone else’s benchmark screenshot. That extra effort upfront will save you a lot of pain later.